mysqldump是mysql自带的一个基本的逻辑备份工具,用于转存储数据库结构和数据。它主要产生一个SQL脚本,其中包含创建数据库所必需的命令CREATE TABLE INSERT等命令。下面总结一下mysqldump的参数,方便日后查询使用。
mysqldump –help
mysqldump Ver 10.13 Distrib 5.6.19-67.0, for Linux (x86_64)
……
# 通过usage可以看出,可以逻辑导出某个数据库、数据库中的表或者全部数据库。一般后面加重定向将逻辑语句写入文件。
Usage: mysqldump [OPTIONS] database [tables]
OR mysqldump [OPTIONS] –databases [OPTIONS] DB1 [DB2 DB3…] #或-B
OR mysqldump [OPTIONS] –all-databases [OPTIONS] #或-A
# 模式和错误输出
Continue reading
Category Archives: Database
MySQL mysqldump
MySQL InnoDB parameter
innoDB是事务型数据库的首选引擎,支持ACID事务,支持行级锁定,也是现在Percona等发型版本的默认引擎。innoDB支持4个事务隔离级,默认为repeatable read,比Oracle支持的两个事务隔离级更加强大。(参考:Innodb事务隔离级别 )
MySQL innodb事务引擎的逻辑框架图和Oracle非常类似,包含一个大的buffer pool,重做日志(redo log),表空间文件ibddata1(等同于Oracle数据文件头+system表空间)。另外,回滚(undo)也不是使用独立的undo表空间来管理undo segment,而是使用主表空间文件。undo相关参考:
概念原理——MySQL数据库InnoDB存储引擎Log漫游
Mysql Innodb的undo redo操作过程
深入分析——InnoDB undo log解析(一)
InnoDB undo log解析(二)
Continue reading
TPCC-MySQL基准测试
TPC(Transactionprocessing Performance Council,事务处理性能委员会)是由数十家会员公司创建的非盈利组织。TPC是制定商务应用基准程序的标准规范、性能和价格度量,并管理测试结果的发布。TPC-C使用三种性能和价格度量,其中性能由tpmC(transactions per minute,tpm)衡量,C指TPC中的C基准程序。它的定义是每分钟内系统处理的新订单个数。TPC-C还经常以系统性能价格比的方式体现,单位是$/tpmC,即以系统的总价格(单位是美元)/tpmC数值得出。(摘自百度百科) Continue reading
Sysbench 0.5 进行基准测试
sysbench是开源的跨平台多线程基准测试工具,主要用于评估测试各种不同系统参数下的CPU、内存、I/O和数据库负载情况。目前sysbench主要支持 MySQL,pgsql,oracle 这3种数据库。本文使用sysbench简单对Percona server5.6.19进行一系列的测试。具体的参数设置,应根据实际环境来进行必要调整。 Continue reading
Percona Server 5.6源码编译
Percona现在没有对el7提供稳定的二进制发行包,所以今天小测一下mysql的源码编译,使用的源码为Percona Server 5.6.19-67,环境为CentOS 7.0。
1. 编译依赖
MySQL的编译依赖下面程序:
g++ MySQL从5.6开始需要使用g++来编译源码。
cmake MySQL从5.5开始,需要使用cmake 2.8+进行工程管理。
bison MySQL的语法解析器用于自动生成语法分析器程序,Bison把LALR形式的上下文无关文法描述转换为可做语法分析的C或C++程序
ncurses-devel 它提供了API,可以允许程序员编写独立于终端的基于文本的用户界面
libaio libaio是Linux下的一个异步非阻塞接口,它提供了以异步非阻塞方式来读写文件的方式,读写效率比较高。
zlib MySQL压缩支持
libxml 用于XML输入输出方式的支持,MySQL的可选功能依赖这个包。
openssl 使用openssl 安全socket方式进行通信
使用yum来安装:
|
1 |
yum install gcc-c++ make cmake bison bison-devel ncurses-devel libaio-devel openssl libxml2 |
MongoDB Shard
分片(Sharding)是一种将海量的数据水平扩展的数据库集群系统。而在MongoDB提供了auto-sharding的功能,通过简单的配置就可以构建一个分布式 MongoDB 分片集群。MongoDB 的数据分块称为 chunk。每个 chunk 都是 Collection 中一段连续的数据记录,通常最大尺寸是 200MB,超出则生成新的数据块。对于数据的分片基于chunk来实现。
一个分片集群包含下面组成(搭建高可用MongoDB集群(四):分片这位大牛已经把高可用shard集群(mongos with replica set)的原理和搭建过程写的很清楚,这里我很无耻的拿来直接实战搞起:),架构上略有不同。
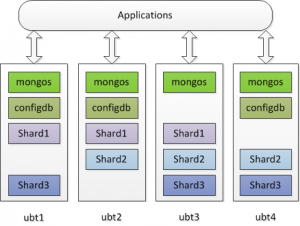
一共使用4台主机,配置了三个configdb。数据三个shard,每个shard为一个3节点的replica set都作为复制节点。如上图所示。这个架构从实际上来说还是有很多问题,这里就不在深究了。 Continue reading
MongoDB Two-phase Commit
先恶补一下分布式事务中事务的各类提交机制:(关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究)
NoSQL并没有关系数据库那么严格的事务机制,所以在NoSQL中能否很好的实现事务功能体现了开发人员的功力。两段式提交保证了分布式XA规范的分布式事务的原子性。两段指prepare阶段和commit阶段:

Continue reading
MongoDB Replica Set
一个replica set可以看作一个带故障转移的Master-Slave复制集群,它在primary节点失效后(或者secondaries不能访问primary时)会自动选举secondary节点成为master。replica set需要保证实例之间相互了解生存状态,所以需要n*(n-1)*2条心跳检测链路。在集群有一定规模时增加了网络的负担。如果使用开发语言的Driver指定了replica set中的一些server,那么driver会自动引入replica set中所有的server并自动在primary失效后故障转移到其他节点。
Replica Set Members
Replica set最多可以有12个成员,但是只有7个成员能同时投票。成员的角色分为:
Primary 同master节点,可以执行write操作。
Secondary 同Slave节点,接收并复制Primary节点的操作。可以进行一些其他配置:如设置为Non-Voting或优先级
Arbiter 不进行数据复制,只在primary失效后参与投票。
Continue reading
MongoDB Master/Slave复制
Master-Slave replication主从复制是最常用的一种高可用模式,常用于备份、故障转移(failover)、读扩展等模式,同样被MongoDB支持,但大多数情况已经被Replica Sets取代。 MongoDB的主从复制配置起来非常简单:
在Master节点,以--master命令行选项或在参数上加上master,并指定日志大小(64MB)。
|
1 2 3 4 5 6 7 |
[root@ubt1] vim /etc/mongo.conf master=true oplogSize=64 #port = 27017 start master server # 启动master mongod [root@ubt1] mongod -f /etc/mongo.conf |
MongoDB Aggregation
《Seven Database in Seven Weeks》提供了一个较好的数据实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
populatePhones =function(country,area,start,stop) { for(var i=start; i < stop; i++) { var country = 1 + ((Math.random() * 8) << 0); var num = (country * 1e10) + (area * 1e7) + i; db.phones.insert({ _id: num, components:{ country: country, area: area, prefix: (i * 1e-4) << 0, number:i }, display:"+"+ country +" "+ area +"-"+i }); } } populatePhones( 86, 855, 5550000, 5650000) populatePhones( 86, 856, 5550000, 5650000) |
那么最终生成的文档如下:
|
1 2 |
db.phones.find().limit(1) { "_id" : 78555550000, "components" : { "country" : 7, "area" : 855, "prefix" : 555, "number" : 5550000 }, "display" : "+7 855-5550000" } |
下面使用上面的文档来测试
|
1 |
count( {} ) |
统计得到的结果的数量
|
1 2 |
> db.phones.count({'components.number': { $gt : 5599999 } })db.phones.count({'components.number': { $gt : 5599999 } }) 50000 |