1. 简介
YARN中基础调度单元是队列(queue),每一个在 容量调度器(Capacity Scheduler)中的队列都有下面属性:
· 短队列名
· 队列路径全名
· 相关子队列和应用的列表
· 队列的保证容量(guaranteed capacity)
· 队列的最大容量(maximum capacity)
· 有效用户和他们相关的资源分配限制的列表
· 队列的状态
· 访问控制列表(ACLs)控制队列的访问 Continue reading
YARN中基础调度单元是队列(queue),每一个在 容量调度器(Capacity Scheduler)中的队列都有下面属性:
· 短队列名
· 队列路径全名
· 相关子队列和应用的列表
· 队列的保证容量(guaranteed capacity)
· 队列的最大容量(maximum capacity)
· 有效用户和他们相关的资源分配限制的列表
· 队列的状态
· 访问控制列表(ACLs)控制队列的访问 Continue reading
Tachyon是一个基于内存的分布式文件系统(项目首页:tachyon-project.org),它是AmpLab的BDAS(berkeley data analytics stack)的一个重要组成。解决了丢失cache导致的重新计算,不同app(job),甚至是不同计算框架间重复的内存使用等问题。目前Spark 1.1默认支持0.5的版本。
Continue reading
要创建一个JobServer项目,需要下面的流程。
1. 在build.sbt中加入jobserver和spark core的package
|
1 2 3 4 5 |
resolvers += "Job Server Bintray" at "http://dl.bintray.com/spark-jobserver/maven" libraryDependencies += "spark.jobserver" % "job-server-api" % "0.4.0" % "provided" libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.1.0" |
续上一篇Spark as a Service之jobServer部署使用开发者模式来测试,本文正式部署并使用jobserver,当前版本有很多BUG和不完善的地方,期待后续的版本修复。
Continue reading
spark-jobserver提供了一个用于提交和管理Apache Spark作业(job)、jar文件和作业上下文(SparkContext)的RESTful接口。该项目位于git(https://github.com/ooyala/spark-jobserver),当前为0.4版本。
“Spark as a Service”: 简单的面向job和context管理的REST接口
通过长期运行的job context支持亚秒级低延时作业(job)
可以通过结束context来停止运行的作业(job)
分割jar上传步骤以提高job的启动
异步和同步的job API,其中同步API对低延时作业非常有效
支持Standalone Spark和Mesos
Job和jar信息通过一个可插拔的DAO接口来持久化
命名RDD以缓存,并可以通过该名称获取RDD。这样可以提高作业间RDD的共享和重用
Continue reading
Spark在YARN中有yarn-cluster和yarn-client两种运行模式: Continue reading
ZooKeeper是一个用于分布式应用程序的分布式开源协调服务。它使用一组简单的操作原语,使得分布式应用可以实现更高层次的服务——如同步、配置维护、群组和命名管理等。ZK具有高性能、高可用(复制)、有序等特征。请参考上一篇译文zookeeper:一个用于分布式应用的分布式协调服务。本文简单介绍一下开发中经常使用的方法(文档:ZooKeeper API)。 Continue reading
ZooKeeper是一个用于分布式应用程序的分布式开源协调服务。它使用一组简单的操作原语,使得分布式应用可以实现更高层次的服务——如同步、配置维护、群组和命名管理等。它以易于编程为基本设计理念,并使用了一个类似于文件系统目录结构风格的数据模型。ZooKeeper服务运行于Java环境中并可以在Java和C中使用。
众所周知,协调服务很难达到正确,尤其会出现竞争条件或死锁等问题。ZooKeeper设计初衷是为了缓解分布式应用从设计到实现中协调服务的问题。 Continue reading
YARN中的资源管理器(Resource Manager)负责整个系统的资源管理和调度,并内部维护了各个应用程序的ApplictionMaster信息,NodeManager信息,资源使用信息等。在2.4版本之后,Hadoop Common同样提供了HA的功能,解决了这样一个基础服务的可靠性和容错性问题。其架构如下:
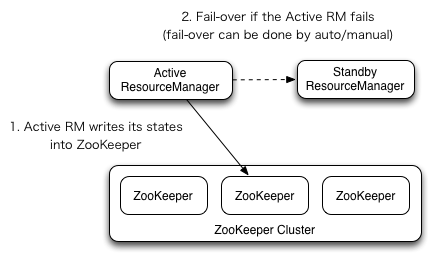
RM HA与NN HA有诸多相同之处(NameNode HA配置详解 ):
(1). Active/Standby架构,同一时间只有一个RM处于活动状态(如上图所示)。
(2). 依赖zooKeeper实现。手动切换使用yarn rmadmin命令(类似hdfs haadmin命令),而自动故障转移使用ZKFailoverController。但不同的是,zkfc只作为RM中一个线程而非独立的守护进程来启动。
(3). 当存在多个RM时,客户端使用的yarn-site.xml需要指定RM的列表。 客户端, ApplicationMasters (AMs)和NodeManagers (NMs) 会以轮训的方式寻找活动状态的RM,也就是说AM
s和NMs需要自己提供容错机制。如果当前活动状态的RM挂掉了,那么会继续使用轮训的方式找到新的RM。这种逻辑的实现需要在yarn.client.failover-proxy-provider中指定使用的类:org.apache.hadoop.yarn.client.RMFailoverProxyProvider
此外,新的RM可以恢复之前RM的状态(详见ResourceManger Restart )。当启动RM Restart,重启后的RM就加载之前活动RM的状态信息并继续之前RM的操作,这样应用程序定期执行检查点操作,就可以避免工作内容的丢失。在Active/standby的RM中,活动RM的状态数据需要active和standby都能访问,使用共享文件系统方法(FileSystemRMStateStore )或者zooKeeper方法(ZKRMStateStore)。后者在同一时间只允许一个RM有写入权限。 Continue reading
HDFS 集群中NameNode 存在单点故障(SPOF )。对于只有一个NameNode 的集群,如果NameNode 机器出现意外downtime,那么整个集群将无法使用,直到NameNode 重新启动。HDFS 的HA 功能通过配置Active/Standby 两个NameNodes 实现在集群中对NameNode 的热备来解决上述问题。如果出现Active NN的downtime,就会切换到Standby使得NN服务不间断。HDFS HA依赖zookeeper,下面是测试的过程。
环境如下
主机:debugo0[1-3],CentOS 6.5
Hadoop 2.4.1
ZooKeeper 3.4.6
| HDFS | ZooKeeper | |
| debugo01 | NN,ZKFC,JournalNode,DN | Server |
| debugo02 | NN,ZKFC,JournalNode,DN | Server |
| debugo03 | NN,JournalNode,DN | Server |