YARN中的资源管理器(Resource Manager)负责整个系统的资源管理和调度,并内部维护了各个应用程序的ApplictionMaster信息,NodeManager信息,资源使用信息等。在2.4版本之后,Hadoop Common同样提供了HA的功能,解决了这样一个基础服务的可靠性和容错性问题。其架构如下:
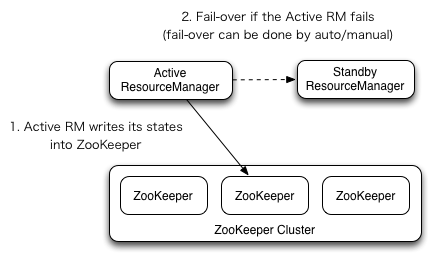
RM HA与NN HA有诸多相同之处(NameNode HA配置详解 ):
(1). Active/Standby架构,同一时间只有一个RM处于活动状态(如上图所示)。
(2). 依赖zooKeeper实现。手动切换使用yarn rmadmin命令(类似hdfs haadmin命令),而自动故障转移使用ZKFailoverController。但不同的是,zkfc只作为RM中一个线程而非独立的守护进程来启动。
(3). 当存在多个RM时,客户端使用的yarn-site.xml需要指定RM的列表。 客户端, ApplicationMasters (AMs)和NodeManagers (NMs) 会以轮训的方式寻找活动状态的RM,也就是说AM
s和NMs需要自己提供容错机制。如果当前活动状态的RM挂掉了,那么会继续使用轮训的方式找到新的RM。这种逻辑的实现需要在yarn.client.failover-proxy-provider中指定使用的类:org.apache.hadoop.yarn.client.RMFailoverProxyProvider
此外,新的RM可以恢复之前RM的状态(详见ResourceManger Restart )。当启动RM Restart,重启后的RM就加载之前活动RM的状态信息并继续之前RM的操作,这样应用程序定期执行检查点操作,就可以避免工作内容的丢失。在Active/standby的RM中,活动RM的状态数据需要active和standby都能访问,使用共享文件系统方法(FileSystemRMStateStore )或者zooKeeper方法(ZKRMStateStore)。后者在同一时间只允许一个RM有写入权限。
一个常见的YARN RM HA配置如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>debugo01</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>debugo02</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>debugo01:2181,debugo02:2181,debugo03:2181</value> <description>For multiple zk services, separate them with comma</description> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-ha</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> <description>Enable automatic failover; By default, it is enabled only when HA is enabled.</description> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name> <value>/yarn-leader-election</value> <description>Optional setting. The default value is /yarn-leader-election</description> </property> <property> <name>yarn.client.failover-proxy-provider</name> <value>org.apache.hadoop.yarn.client.RMFailoverProxyProvider</value> </property> |
同时,yarn RM服务监听地址的设置要修改成下面的方式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
<property> <name>yarn.resourcemanager.address.rm1</name> <value>debugo01:8132</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>debugo02:8132</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>debugo01:8130</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>debugo02:8130</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>debugo01:8131</value> </property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>debugo02:8131</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>debugo01:8188</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>debugo02:8188</value> </property> |
启动RM
start-yarn.sh
在standby的节点单独启动RM(也可使用start-yarn.sh脚本)
检查状态:
|
1 2 3 4 |
$ yarn rmadmin -getServiceState rm1 active $ yarn rmadmin -getServiceState rm2 standby |
访问rm2节点的nodemanager会提示
This is standby RM. Redirecting to the current active RM: http://debugo01:8188/cluster/apps
下面KILL掉rm1的resourcemanager
|
1 2 3 4 5 |
[hadoop@debugo01 logs]$ yarn rmadmin -getServiceState rm2 active [hadoop@debugo01 logs]$ yarn rmadmin -getServiceState rm1 14/09/14 03:08:23 INFO ipc.Client: Retrying connect to server: debugo01/192.168.46.201:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS) Operation failed: Call From debugo01/192.168.46.201 to debugo01:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused |
参考
http://hadoop.apache.org/docs/r2.4.1/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
http://dongxicheng.org/mapreduce-nextgen/hadoop-yarn-ha-in-cdh5/
这让之前某只在站里不遗余力宣讲转基因安全可靠的某大仙情何以堪啊?
清澈如水,看似平淡,立意高远,实非屑小所能望其项背。向老乡问好!