Hue(http://gethue.com/)全称是Hadoop User Experience,由Cloudera开发,是一个用于数据分析的Apache Hadoop的Web接口。
它提供的功能包括:
一个HDFS的文件浏览器
一个MapReduce/YARN的作业浏览器
一个Hive、HBase,Cloudera Impala 和 Sqoop2 的查询编辑器。
它还附带了一个Oozie的应用程序,用于创建和监控工作流程。后期数据可视化功能也非常强大!是不是觉得很高大上啊!下面我们一起使用一下东西。
1. HUE部署
CDH 5.x中都集成了HUE这个模块,本文使用的版本是CDH5.3.2。
Hue 可以通过下面两种方式访问 Hdfs 中的数据:
WebHDFS:提供高速的数据传输,客户端直接和 DataNode 交互
HttpFS:一个代理服务,方便与集群外部的系统集成
两者都支持 HTTP REST API,但是 Hue 只能配置其中一种方式;对于 HDFS HA部署方式,只能使用 HttpFS。所以在运行HUE之前,我们需要准备HDFS,HBase,Hiveserver2,HBase等基础服务,并启动httpfs服务。
安装httpfs和HUE
|
1 |
yum install hadoop-httpfs hue httpfs |
确认/etc/hadoop-httpfs/conf/httpfs-site.xml包含HUE的代理用户和组:
|
1 2 3 4 5 6 7 8 |
<property> <name>httpfs.proxyuser.hue.hosts</name> <value>*</value> </property> <property> <name>httpfs.proxyuser.hue.groups</name> <value>*</value> </property> |
启动httpfs服务
|
1 |
service hadoop-httpfs start |
确认$HADOOP_CONF_DIR/core-site.xml包含以下参数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<property> <name>hadoop.proxyuser.httpfs.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.httpfs.groups</name> <value>*</value> </property> <property> <name>httpfs.proxyuser.hue.hosts</name> <value>*</value> </property> <property> <name>httpfs.proxyuser.hue.groups</name> <value>*</value> </property> |
完成后要重启hadoop以生效。
2. 配置Hue
HUE需要指向HiveServer2。因此需要更新/etc/hue/conf/hue.ini如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
[beeswax] # Host where Hive server Thrift daemon isrunning. # If Kerberos security is enabled, usefully-qualified domain name (FQDN). ## hive_server_host=localhost hive_server_host=debugo02 # Port whereHiveServer2 Thrift server runs on. ## hive_server_port=10000 hive_server_port=10000 # Hiveconfiguration directory, where hive-site.xml is located ## hive_conf_dir=/etc/hive/conf hive_conf_dir=/etc/hive/conf |
hive_server_host, hive_server_port参数配置为HiveServer2所在主机和端口。
(2) 配置Hue的端口与访问地址
编辑/etc/hue/conf/hue.ini的desktop属性,配置Web UI监听地址和端口。
|
1 2 3 4 5 6 7 8 9 |
[desktop] # Set this to a random string, the longer thebetter. # This is used for secure hashing in thesession store. secret_key= # Webserver listens on this address and port http_host=0.0.0.0 http_port=8888 time_zone=Asia/Shanghai |
YARN_Cluster的部分,配置RM的地址。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
[[yarn_clusters]] [[[default]]] # Enter the host on which you are runningthe ResourceManager ## resourcemanager_host=localhost resourcemanager_host=debugo01 # The port where the ResourceManager IPClistens on ## resourcemanager_port=8032 resourcemanager_port=8032 # Whether to submit jobs to this cluster submit_to=True # Resource Manager logical name (requiredfor HA) ## logical_name= # Change this if your YARN cluster isKerberos-secured ## security_enabled=false # URL of the ResourceManager API ##resourcemanager_api_url=http://localhost:8088 resourcemanager_api_url=http://debugo01:8088 # URL of the ProxyServer API ## proxy_api_url=http://localhost:8088 # URL of the HistoryServer API ##history_server_api_url=http://localhost:19888 history_server_api_url=http://hadoop01:19888 |
启动HUE:
|
1 |
service hue start |
3. 使用HUE
浏览器登录http://debugo02:8888
首次登陆创建超级用户:hue/hue。登录后我们可以到右上角的管理里,创建一个用户。比如:hdfs/hdfs
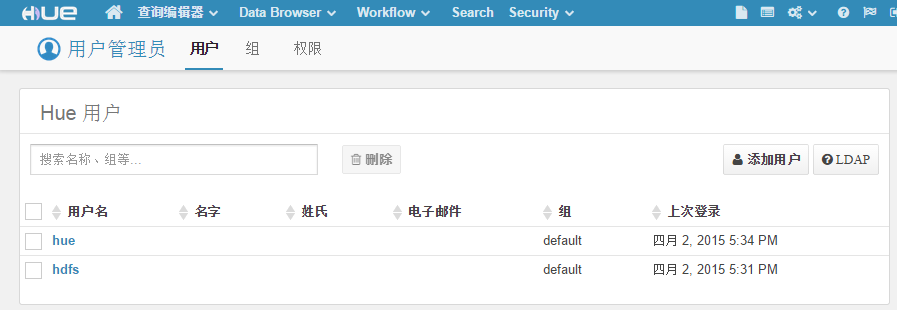
右上角的管理HDFS,可以让我们来操作HDFS的内容。
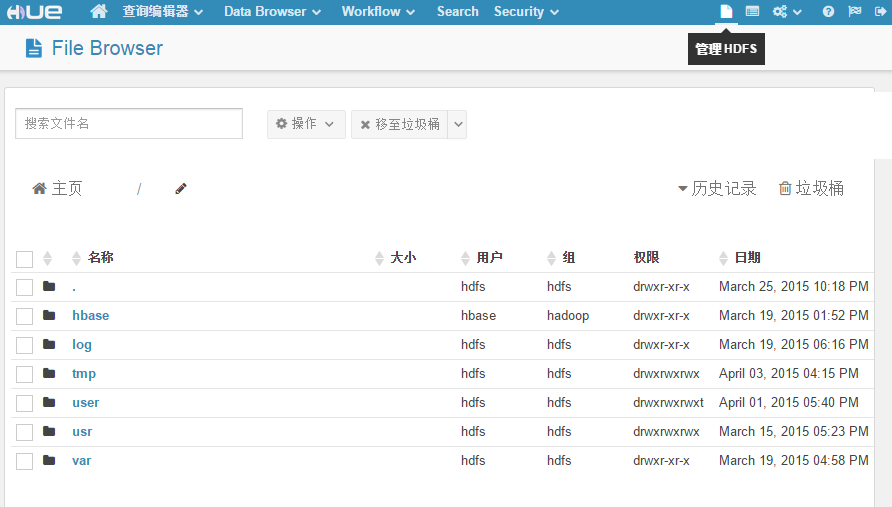
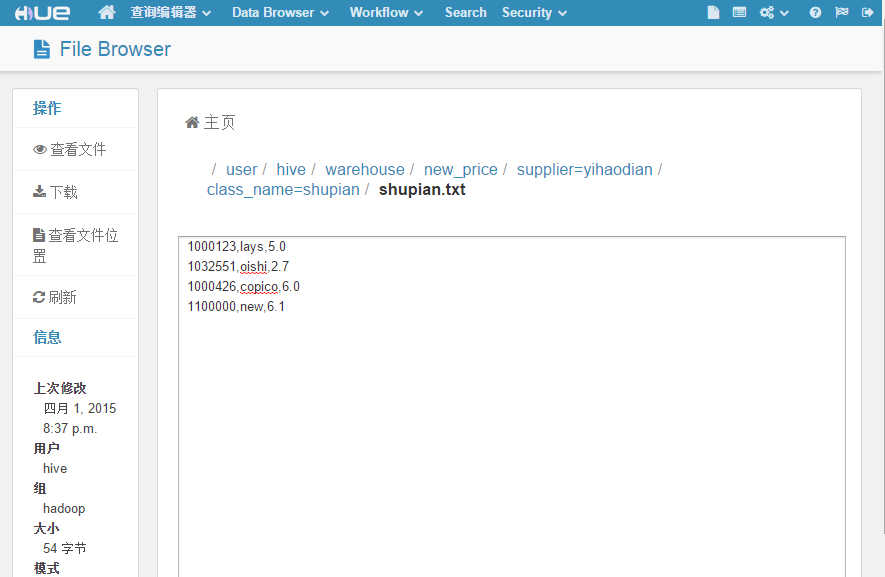
可以直接在这个图形界面上传/下载文件,甚至可以直接编辑文件。(目测如果文件太大的情况下会不太稳定)。
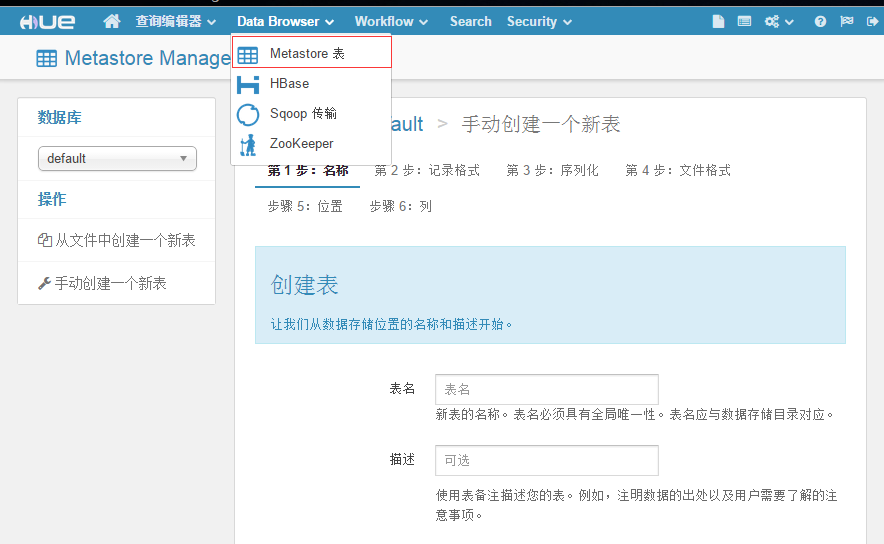
在查询编辑器——Hive中,我们可以看到数据库下面所有的表信息,并能执行HQL语句,非常方便。
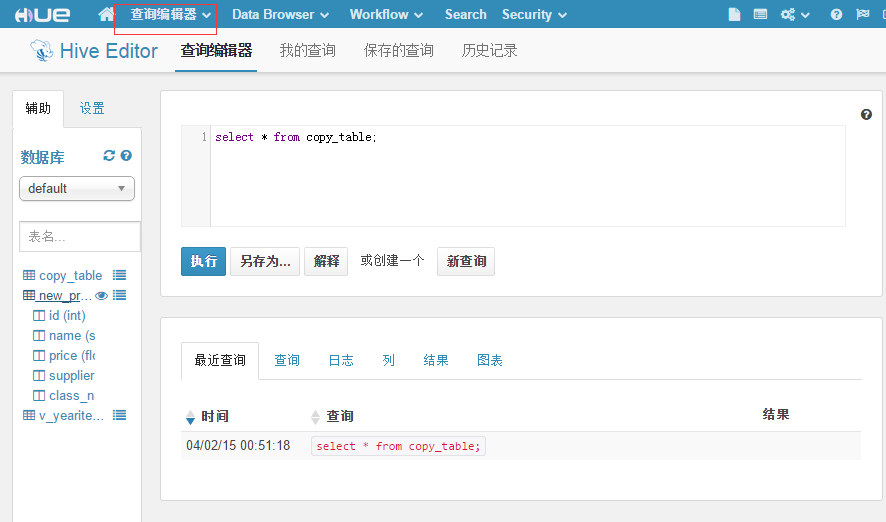
定义新表:
这些功能仅仅是HUE的冰山一角,其他功能还包括:
> 执行impala的查询
> 执行其他RDBMS的查询
> 查看和编辑HBase的模式
> Pig编辑器/执行器
> 执行Sqoop作业
> 查看ZooKeeper节点和目录
> 提交Spark作业(上传jar)并执行,结果可以即时的显示出来。
> 设计作业任务(作业的类型可以是Java,MR,Streaming,Hive,pig,sqoop,FS,SSH,Shell,Email,Distcp),这里可以上传对应的jar或者脚本
> 将指定的作业任务编辑一个工作流(workflow)并可调度
> 执行solr搜索
> 配置HDFS ACL和Sentry
> 查看YARN上正在运行的作业
当然对于每个具体的功能,都需要去具体的配置文件中写入相关的信息。HUE的功能可以说涉及到大数据工作的方方面面,通过在界面的配置就完成了绝大多数大数据工作,避免去集群上提交作业、查询相关信息。高效的大数据工作从此走起!
^^
老师,能问一下 你这个博客 使用的wordpress吗
是的,wordpress 4的版本。
来瞅瞅啦~
传奇私服http://bbs.caipiaodian.com.cn/ 传奇私服sf传奇私服http://www.banshouseo.com/ 传奇服务端传奇私服http://www.zhanzhangzhiwang.com/ GM论坛传奇论坛http://www.banshouseo.net/ 传奇私服传奇私服http://lol.v58.org/ 传奇论坛
不错不错,来看看。。
今天才发现你的博客,连着看了几篇呢 http://www.xevip.cn
今天才发现你的博客,连着看了几篇呢
万 部 A 片高清 国产 日韩 http://uVU.cc/inRx
⸄嫩模性感护士图片人体艺术图片爱如潮水性感丝袜性感人体艺术hTtP://5729.mm88.gq
ﭗ私房照ﭗ人体艺术图片选美比赛比基尼京剧武大女神赏樱写真瑞丽写真360meimei.com
丝足高跟⫊春妮丝袜⫊偷丝袜文章⫊7e.518mei.com
性感宝贝⿻31岁小美女的养颜经古代美女换装中国人体艺术照片性感少女图av天堂吧美女图片壁纸www.mm520.ga
߰制服美女性感沙滩3中文版www.mm88.ml
L美女套图美胸明星排行榜美胸美女美少女人体艺术图片上海艺术写真r人体艺术hTTp://T.cN/R6bPO9N
作者快点更新